2021年12月13日,计算机学院“Time·前沿”论坛第三期邀请了南加州大学著名教授Viktor K. Prasanna主讲“Accelerating Graph Neural Networks”,众多师生专家学者通过zoom线上会议室聆听演讲,进行了热烈讨论。

图神经网络(GNN)在机器学习领域的应用非常广泛,但计算开销制约了GNN的扩展性,Viktor教授介绍了GNN的发展现状及应用,分析了数据规模、数据复用、随机访存、负载不均和异构内核等GNN加速面临的挑战。针对这些问题,Viktor教授重点介绍了两项突破性研究成果,对下游应用性能优化具有重要意义。
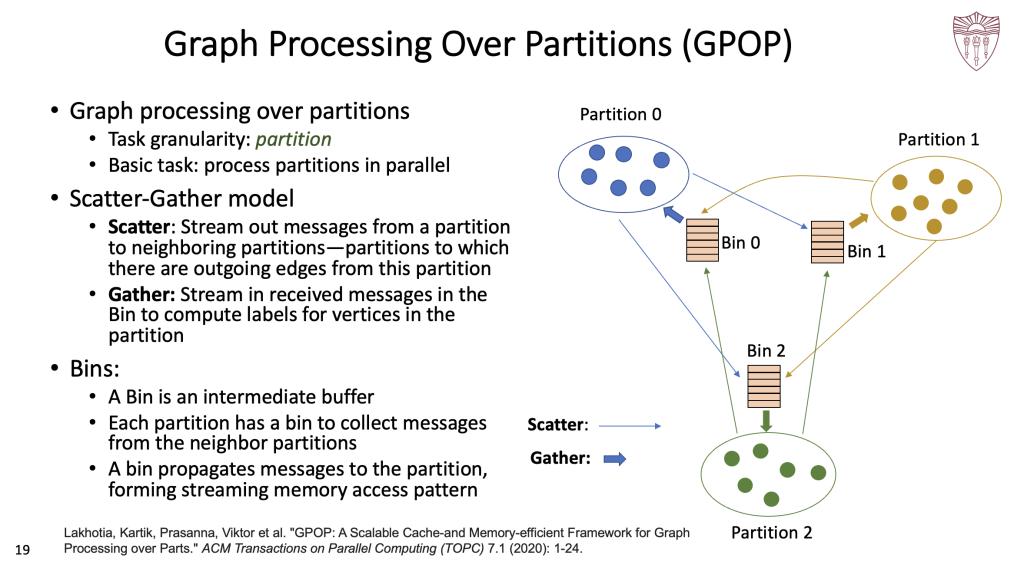
Viktor教授介绍的第一项研究成果是基于图划分的方法Graph Processing Over Partitions(GPOP),该方法主要针对图像处理阶段进行加速,将图像划分为小粒度子图进行并行处理来提升性能。GPOP采用的是Scatter-Gather并行计算模型,该模型分为Scatter和Gather两个阶段。Scatter阶段将节点信息以流的形式传递给邻居节点,Gather阶段收集子图信息用于节点标签计算。同时,GPOP设计了流存储访问模式,将Bin中间缓存作为信息传递媒介,从而通过并行处理每个划分和多轮迭代来加速图计算。
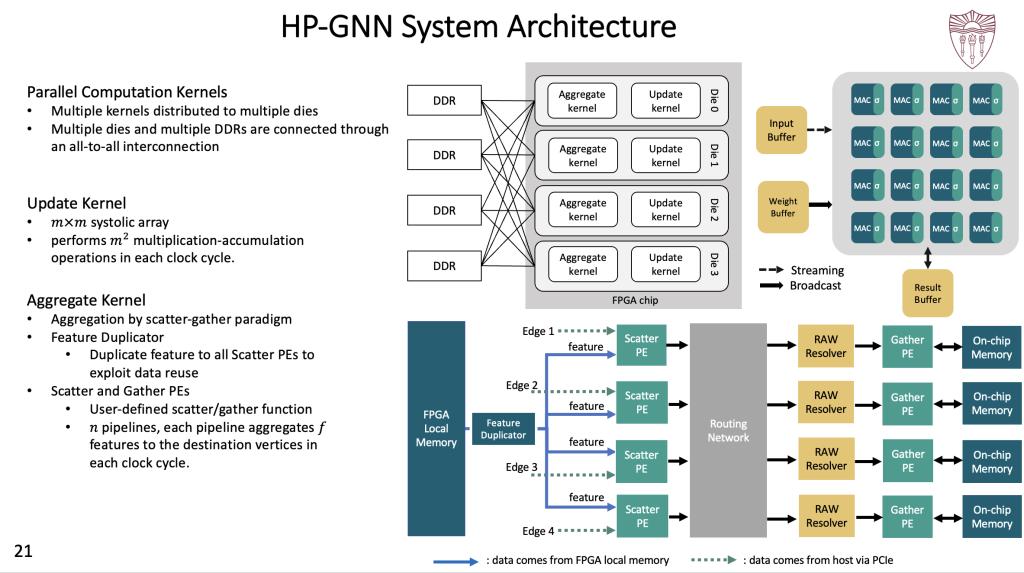
第二项研究成果是利用CPU+FPGA平台对基于采样的GNN计算加速(HP-GNN),给定GNN参数以及CPU+FPGA平台元数据,HP-GNN通过硬件内核优化可以对各类基于采样的GNN模型训练进行加速。HP-GNN架构包含并行计算内核、更新内核和聚合内核三大部分,并行计算内核分布于不同裸片,这些裸片和DDR与FPGA芯片以全连接的方式进行连接,更新内核在每个时钟周期进行乘法累积运算,再由特征聚合内核利用自定义的Scatter-Gather模型进行数据复用和聚合运算,最终将结果输出给宿主程序。同时,HP-GNN设计了友好的API来屏蔽硬件架构,用户通过API可以方便地利用CPU+FPGA平台加速GNN模型训练。
Viktor K. Prasanna是南加州大学电气工程和计算机科学教授、能源信息中心主任、ACM/IEEE/AAAS Fellow,主要在高性能计算、并行和分布式系统、云计算和智能能源系统领域开展研究工作。Viktor教授长期担任国际并行与分布式处理研讨会(IPDPS)和高性能计算国际会议(HiPC)的指导委员会联合主席,是IEEE计算机学会并行处理技术委员会的创始主席,目前担任《并行和分布式计算杂志》(JPDC)主编。Viktor教授在2010年获得IEEE计算机协会颁发的杰出服务奖,于2015年获得了W. Wallace McDowell奖,曾在ACM计算前沿(CF)、IEEE国际并行和分布式处理研讨会(IPDPS)、ACM/SIGDA现场可编程门阵列国际研讨会、并行和分布式系统国际会议(ICPAD)等多个国际会议和期刊上获得最佳论文奖。
来源:计算机学院新闻中心
作者:郜勇勇 万静意

